Find Duplicates in List Python
We often need to find duplicates in a list in Python. Either we need to remove them or we need to perform some operation on them or we need to find the frequency of each duplicate element.
In this article, we will learn how to find duplicates in a list in Python. With this we will also cover different related operation on duplicates like removing duplicates, finding frequency of each duplicate element, etc.
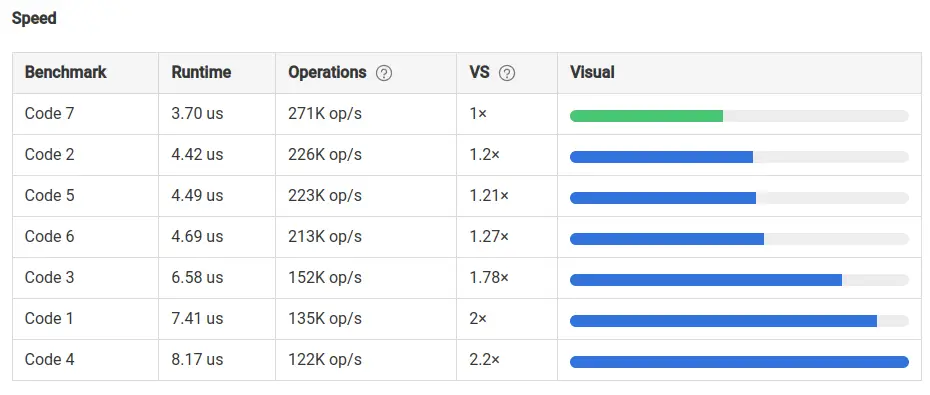
Speed comparison of each method is also given at the end of this article.
Python Program to Find Duplicates in a List
Let's see different ways to find duplicates in a list in Python.
1: Using Naive Method
One of the simplest method to find duplicates in a list is to use two nested loops.
The outer loop will iterate through the list and the inner loop will check if the current element of the outer loop is equal to any of the elements of the list.
If the current element of the outer loop is equal to any of the elements of the list, then we will print that element.
my_list = [10, 12, 14, 10, 16, 14, 18]
# nested loops to find duplicates
for i in range(len(my_list)):
for j in range(i+1, len(my_list)):
if my_list[i] == my_list[j]:
print(my_list[i])
breakOutput:
10 14
Here, we have used break statement to avoid printing the duplicate element multiple times.
2: Using Set
A Set() only contains unique elements.
We can use loop through the list and if number of element in list is more than 1, then we can add that element to a set. At the end, we will have a set containing all the duplicate elements.
my_list = [10, 12, 14, 10, 16, 14, 18]
# set to store duplicate elements
duplicate = set()
for num in my_list:
# count number of times element appears in the list
if my_list.count(num) > 1:
duplicate.add(num)
print(duplicate)Output:
{10, 14}
Here, we have used count() method to count the number of times an element appears in the list.
3: Using single loop and count() method
Complexity of nested loops is O(n2). We can reduce the complexity to O(n) by using a single loop and count() method.
We will loop through the list and check if the current element appears more than once in the list. If it does, then we will push it in another list by checking if it is already present in the list or not.
my_list = [10, 12, 14, 10, 16, 14, 18]
# list to store duplicate elements
duplicate = []
for num in my_list:
# check if it is duplicate of not
if my_list.count(num) > 1:
# check if it is already present in the list or not
if num not in duplicate:
duplicate.append(num)
print(duplicate)Output:
[10, 14]
4: Using Counter() method
The Counter() method is used to count the number of times an element appears in a list.
Here is how we can use it to find duplicates in a list.
from collections import Counter
my_list = [10, 12, 14, 10, 16, 14, 18]
# counter() method returns dictionary of elements
# in list as keys and their frequency as value
duplicates = [item for item, count in Counter(my_list).items() if count > 1]
print(duplicates)Output:
[10, 14]
We used list comprehension to create a list of duplicate elements.
5: Using clist comprehension and count() method
The count() method also returns the number of times an element appears in a list.
We can use it to find duplicates in a list.
my_list = [10, 12, 14, 10, 16, 14, 18]
# create a list of duplicate elements
duplicates = list(set([num for num in my_list if my_list.count(num) > 1]))
print(duplicates)Output:
[10, 14]
6: Using Dictionary
You can create a with elements of the list as keys and their frequency as values. Then you can loop through the dictionary and print the keys whose value is greater than 1.
my_list = [10, 12, 14, 10, 16, 14, 18]
# create a dictionary with elements
# as keys and their frequency as values
duplicates = {num:my_list.count(num) for num in my_list}
# create a list of duplicate elements
duplicates = [key for key in duplicates if duplicates[key]>1]
print(duplicates)Output:
[10, 14]
7: ⭐️⭐️⭐️Using combination of operator and count() method
Using logics with operators like in, not in, ==, !=, etc. can also help us to find duplicates in a list.
Here is how we can use them to find duplicates in a list.
my_list = [10, 12, 14, 10, 16, 14, 18]
# create a list of duplicate elements
duplicates = []
for num in my_list:
if my_list.count(num) > 1 and num not in duplicates:
duplicates.append(num)
print(duplicates)Output:
[10, 14]
Conclusion
We have seen different ways to find duplicates in a list in Python. You can choose any of them according to your need.
Out of all the methods, the fastest method 7th one (using single loop with operators), here is screenshot of the time taken by each method.